





Il mondo dell’intelligenza artificiale generativa è in continua evoluzione, con gli sviluppatori che ogni giorno mettono a segno nuovi progressi per rendere le creazioni sempre più verosimili. Microsoft Research, per esempio, ha presentato in questi giorni VASA-1, un’AI in grado di generare video estremamente verosimili partendo da una singola fotografia di un volto: praticamente il paradiso dei deep fake.
Da una singola foto, VASA-1 genera un video con audio ed espressioni facciali
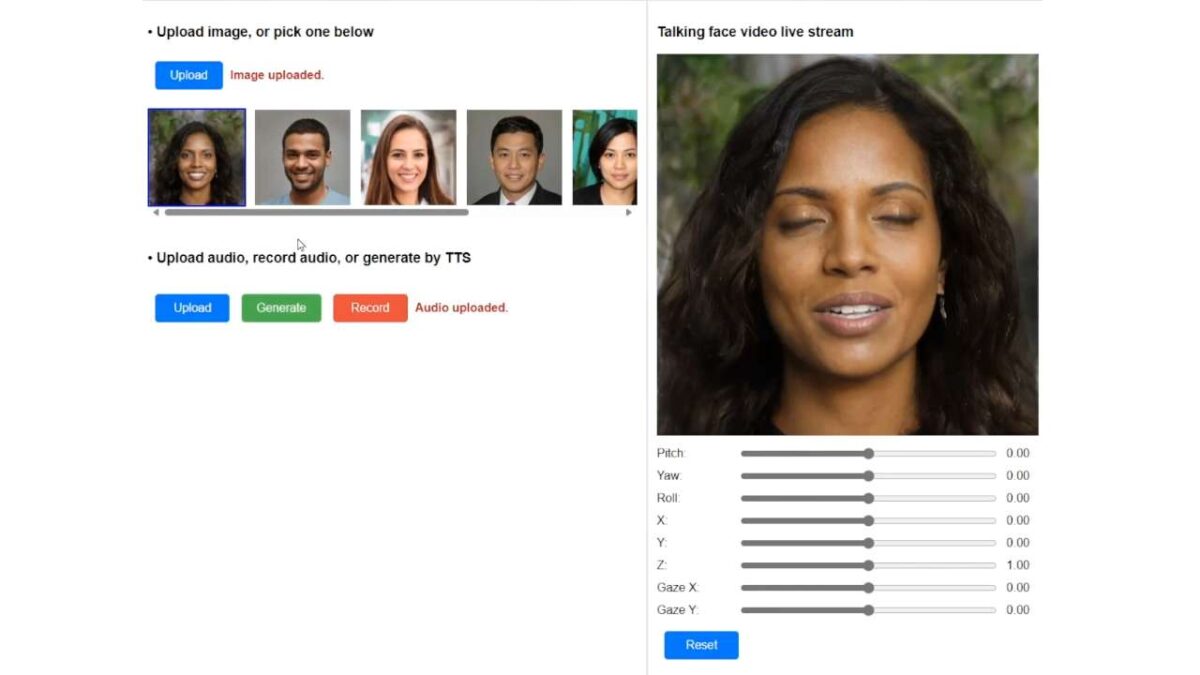
La divisione Research di Microsoft ha presentato ufficialmente VASA, un framework per generare volti parlanti realistici di personaggi virtuali con abilità visive affettive (VAS) accattivanti, partendo da una singola immagine statica e una clip audio vocale. Il modello VASA-1 è in grado non solo di produrre movimenti delle labbra perfettamente sincronizzati con l’audio, ma anche di catturare un ampio spettro di sfumature facciali e movimenti naturali della testa che contribuiscono alla percezione di autenticità.
Questa intelligenza artificiale, partendo da una singola immagine, è in grado di generare filmati con una risoluzione 512 x 512 pixel a 40 FPS per una durata massima di 1 minuto. Negli esempi che potete visualizzare sul sito ufficiale del progetto, i risultati sono davvero strabilianti: le espressioni facciali vengono riprodotte con estrema accuratezza, anche su volti disegnati o creati in computer grafica.
Microsoft conosce bene i rischi che comporta una tecnologia del genere e per questo motivo ha deciso di non pubblicare online alcuna demo utilizzabile dal pubblico. Lo stesso progetto, inoltre, non fornirà mai accesso ad alcuna API che possa sfruttare in qualche modo l’AI di VASA-1.
Sai che siamo anche su WhatsApp? Iscriviti subito ai canali di GizChina.it e GizDeals per restare sempre informato sulle notizie del momento e sulle migliori offerte del web!
⭐️ Scopri le migliori offerte online grazie al nostro canale Telegram esclusivo.")
