






Siamo finalmente arrivati alla fine del nostro “teardown mentale” in cui, un componente dopo l’altro, abbiamo disassemblato i nostri smartphone per capirne il funzionamento e le possibili evoluzioni. Dopo aver analizzato gli elementi strutturali ed i sistemi che rendono possibile l’interazione dei dispositivi con l’ambiente circostante e con la rete, infatti, questa settimana concluderemo il nostro viaggio parlando di quei componenti che costituiscono il cervello di ogni device.
Ci riferiamo naturalmente a RAM e ROM, che si comportano rispettivamente come memoria a breve termine ed a lungo termine, ed al SoC, che si occupa di interpretare ed elaborare tutte le informazioni che arrivano dai tanti sensori del terminale. Oggi scopriremo quindi i principi teorici che sono alla base del funzionamento dell’intero sistema, apprezzeremo le potenzialità dell’architettura ARM e l’elevata integrazione raggiunta nei SoC e, infine, analizzeremo i tipi di memoria che rendono possibile la conservazione dei dati.

Il prossimo articolo, invece, sarà dedicato alle più importanti tendenze tecnologiche riguardo l’evoluzione di questi componenti, come la corsa alle prestazioni (e le vie che possono essere seguite per raggiungere questo obbiettivo), l’utilizzo di sistemi di risparmio energetico e la ricerca di memorie più veloci, economiche e dense. Non mancheranno poi i riferimenti alla corsa verso la miniaturizzazione ed alla legge di Moore, né agli ultimi ritrovati della tecnica ed alle loro promesse.
Nel normale utilizzo siamo abituati ad impartire comandi ai nostri terminali senza chiederci cosa accade realmente “sotto la scocca”. Anche osservando dall’esterno il device, tuttavia, è possibile capire alcuni dei presupposti logici su cui si basa l’intero sistema. Possiamo notare, ad esempio, che l’output (che potrebbe essere quel che vediamo sullo schermo) dipende sia dagli input (dati in arrivo dai sensori e dalla rete) che dallo stato in cui si trova il device, o ancora che a parità di input e di stato iniziale il sistema evolverà sempre nello stesso modo.
Per comprendere meglio il funzionamento dei nostri dispositivi, comunque, ci converrà guardare sempre più in dettaglio la loro struttura. Ad un primo livello, quindi, noteremo che i componenti principali sono un’unità di lavoro (il processore), una memoria principale (RAM) e varie unità di input ed output. Lo scambio dei dati tra le varie parti del sistema, inoltre, sarà gestito da un bus di comunicazione che, per ottimizzare consumi e costi, è ospitato direttamente nel SoC.

Abbiamo appena delineato l’architettura di una macchina di Von Neumann che, in effetti, in prima approssimazione descrive bene il funzionamento del sistema. La memoria principale, in particolare, in questo schema ospiterà sia i dati da manipolare che le liste di istruzioni che costituiscono i programmi eseguibili.
In una macchina di Von Neumann classica, d’altra parte, il processore è abbastanza semplice ed è composto sostanzialmente da un contatore di programma (PC), un registro per le istruzioni, un’unità aritmetica e logica (ALU) e dei circuiti di controllo (CU). Il ciclo inizierà leggendo dal contatore l’indirizzo dell’istruzione da eseguire, che sarà a sua volta letta dalla memoria e caricata nel registro (fase di fetch).

La logica di controllo, a questo punto, interpreterà l’istruzione, la farà eseguire dall’ALU (execute) ed incrementerà il PC per passare al’istruzione successiva. Saranno possibili inoltre salti condizionati, che al verificarsi di precise condizioni agiranno sul contatore di programma, e il ciclo terminerà solo quando sarà caricata una opportuna istruzione di ALT.
Il SoC dei nostri dispositivi, invece, è molto complesso e contiene svariati processori, tutti caratterizzati da architetture raffinate ed estremamente ottimizzate per i compiti che devono svolgere. Alcuni di questi sotto-sistemi, comunque, sono stati sviluppati a partire dalla macchina di Von Neumann, mentre altri sono basati su quella di Harvard in cui la memoria per le istruzioni e quella per i dati sono separate.

Quest’ultimo approccio, in particolare, è molto apprezzato perché permette di ridurre drasticamente il tempo necessario ad alcune operazioni. Questi sistemi, infatti, si muovono tra stati discreti il cui evolversi è scandito dal clock, un segnale periodico generato da un oscillatore che è utilizzato per sincronizzare il funzionamento delle varie unità. La disponibilità di memorie separate consente, quindi, di caricare contemporaneamente (nello stesso clock) sia i dati che le istruzioni.
Questo vantaggio ha portato allo sviluppo di architetture ibride che, viste esternamente, sono del tipo di Von Neumann ma, internamente, dispongono di due velocissime memorie dedicate (cache L1). Queste, grazie a potenti algoritmi di prefetch, conterranno rispettivamente i dati e le istruzioni che con maggiore probabilità saranno necessari nei cicli successivi, rendendo il cuore del sistema di tipo Harvard. Il caso dei nostri SoC, poi, è ancora più complesso perché dispone di una CPU (central processing unit) multicore, in cui si utilizzano memorie aggiuntive condivise tra i core (cache L2 e L3) per consentire un rapido scambio di informazioni tra questi.

Anche il singolo core, poi, di solito è molto più complicato di quello che abbiamo appena descritto. Per aumentare le performance, ad esempio, si ricorre spesso ad una struttura a pipeline, in cui le istruzioni vengono eseguite “a catena di montaggio” con un circuito dedicato ad ogni stadio. In questo modo, quindi, è possibile l’elaborazione di più istruzioni in contemporanea, in quanto i vari stadi posso agire nello stesso momento (iniziando un’istruzione prima che finisca la precedente).
Questo sistema, in realtà, può funzionare solo quando le istruzioni hanno un buon grado di parallelismo (ILP), cioè quando sono poco correlate e non hanno bisogno del risultato di un codice che è ancora in fase di elaborazione. Questo tipo di parallelismo può essere ulteriormente sfruttato, poi, con l’utilizzo di architetture superscalari, in cui un dispatcher smista le istruzioni a diverse pipeline all’interno dello stesso core.

Queste potenti tecnologie, comunque, sono molto rischiose e, se non implementate bene, in alcuni casi possono portare ad una drastica diminuzione delle prestazioni. Quando è presente un salto condizionato, ad esempio, è possibile che le istruzioni caricate in pipeline non siano quelle “giuste”, cioè quelle che realmente saranno richieste dal programma. Nel caso peggiore si dovrà quindi attendere lo svuotamento della pipeline, con conseguente spreco di preziosi cicli di clock.
Per evitare questi sprechi si utilizzano dei circuiti appositi, che hanno il ruolo di analizzare le istruzioni per massimizzare l’utilizzo delle unità di calcolo. Il caso dei salti condizionati, quindi, richiederà una buona unità di branch prediction, mentre l’esecuzione speculativa (in cui si esegue un codice che potrebbe non essere necessario) e quella out of order (che consente di anticipare le istruzioni i cui dati sono già disponibili per evitare attese inutili) consentono di eseguire complessivamente più di un’istruzione per ciclo di clock (IPC).
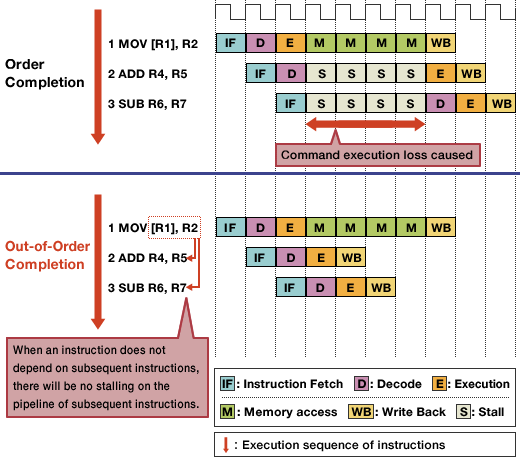
Quando si devono eseguire le stesse istruzioni su più dati, poi, è possibile che alcuni stadi della pipeline vengano saltati (se non necessari, come quelli di fetch) o che siano presenti unità single instruction multiple data (SIMD) che eseguono calcoli vettoriali. Non dobbiamo dimenticare infine la presenza di altre unità dedicate come la FPU che, a differenza dell’ALU, può effettuare anche calcoli in virgola mobile (esponenziali e trigonometrici).
Adesso che abbiamo visto le tecnologie più comunemente utilizzate per la creazione di processori, dobbiamo chiarire che la specializzazione d’uso ha un ruolo importantissimo nel definire l’architettura finale del singolo elemento. Per eseguire calcoli generici, ad esempio, sarà conveniente avere un processore con frequenze operative abbastanza elevate e dotato di pochi core grandi e flessibili, mentre per calcoli ripetitivi facilmente parallelizzabili (come quelli multimediali) si tenderà a sfruttare un numero molto elevato di core piccoli e efficienti (ma meno versatili).
Abbiamo appena delineato, di fatto, la differenza sostanziale che esiste tra una CPU ed una GPU (graphics processing unit): la prima può essere vista come un aereo supersonico che porta velocemente poche persone alla volta, la seconda come un aereo di linea che trasporta più lentamente un numero elevato di passeggeri. I SoC (System on a chip) dei nostri smartphone, che hanno bisogno della massima flessibilità e di consumi bassi, integrano al loro interno svariati processori dedicati ai vari scenari d’uso, in modo da poter sempre effettuare il calcolo al massimo dell’efficienza.

I SoC per smartphone attualmente più diffusi, in particolare, utilizzano una CPU basata su architettura ARMv7A a 32 bit, mentre si stanno lentamente imponendo quelli basati su ARMv8A a 64 bit. Queste architetture trovano espressione sia nei core Cortex disegnati direttamente da ARM, che in diversi prodotti proprietari che le hanno ottenute in licenza, come il core Krait di Qualcomm o quelli sviluppati internamente da Apple.
È importante, comunque, che tutti questi core diversi siano compatibili con gli stessi set di istruzioni e possano, di conseguenza, utilizzare lo stesso codice indipendentemente dal costruttore. Dobbiamo dire per completezza, inoltre, che l’architettura ARM è di tipo RISC (reduced instruction set computer) ed utilizza, di conseguenza, istruzioni semplici di lunghezza fissa che raramente prevedono l’accesso alla memoria. Questo approccio consente di creare CPU piccole e semplici, dalla grande efficienza e quindi perfette per l’ambito mobile.
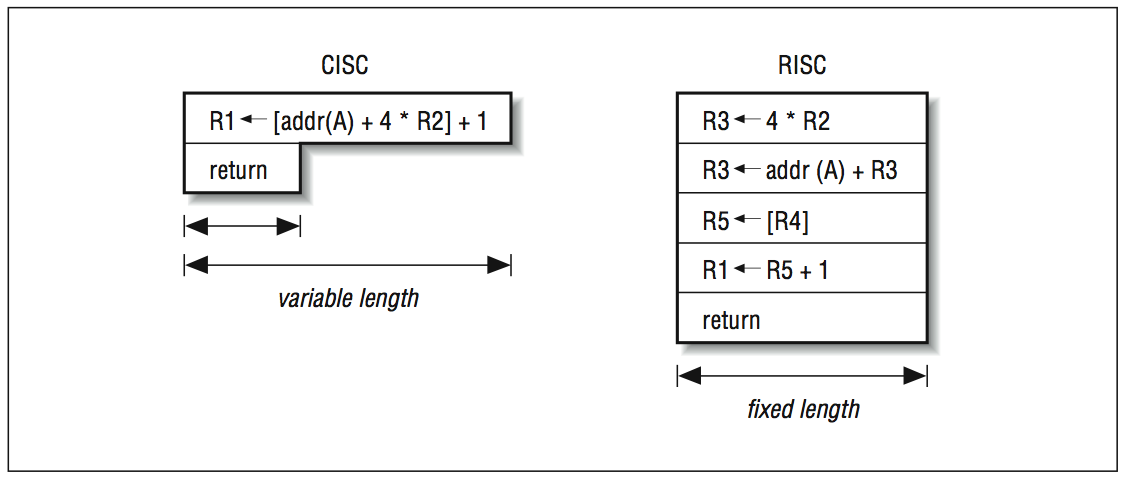
L’approccio alternativo CISC (Complex instruction set computer), che è seguito ad esempio dall’architettura x86 di Intel e dai suoi derivati, prevede invece la presenza di un gran numero di istruzioni lunghe e complesse. Purtroppo tale tecnologia si è dimostrata nel tempo sempre più difficile da implementare e costosa in termini di spazio sul silicio, tanto che i moderni processori CISC di solito traducono le istruzioni complesse in numerose micro operazioni che vengono svolte da un processore che, a valle della decodifica, è molto simile ad un RISC.
I SoC per smartphone più comuni, dunque, contengono di solito alcuni core ARM o Intel che, a seconda delle varie incarnazioni, possono contare su unità SIMD (NEON per ARM e SSE per Intel), su differenti quantità di cache e su un design in order (i meno performanti) o out of order. Accanto a questi è poi presente il controller di memoria, la GPU (spesso basata su architetture ARM Mali, Qualcomm Adreno o Imagination Technologies PowerVR) e il display processor, che si occupano rispettivamente dialogare con la RAM, di calcolare le immagini 3D e di gestire lo schermo.
Sono poi numerosi i DSP (digital signal processor), utilizzati per eseguire in maniera estremamente efficiente algoritmi di uso comune come quelli per la gestione dei sensori, per la rimozione dei disturbi e per la compressione e decompressione dei file multimediali. Meno flessibile è invece l’ISP (image signal processor), che nasce solo per la gestione delle fotocamere e si occupa di effettuare tutti quei passaggi software che abbiamo visto nei nostri articoli dedicati all’argomento.
Non manca infine il modem (che gestisce la connessione alle reti cellulari, al Wifi e a tutte le altre tecnologie di comunicazione che abbiamo già incontrato la scorsa settimana) né i circuiti dedicati al calcolo della posizione tramite rilevamento satellitare. Tutti questi elementi sono collegati tra loro, per concludere, da un bus di comunicazione, di solito basato sullo standard AMBA (Advanced Microcontroller Bus Architecture).
Il risultato dei calcoli effettuati dai tanti processori presenti nel SoC devono necessariamente essere immagazzinati in memorie più capienti delle piccole cache integrate in quest’ultimo e, seguendo l’architettura di Von Neumann, trovano una prima accoglienza nella memoria primaria. Questa deve essere particolarmente veloce per non rallentare il funzionamento dell’intero sistema e la scelta, di conseguenza, ricade di solito sulle memorie ad accesso casuale (RAM).
Queste si caratterizzano per il fatto che il tempo di accesso ai dati non dipende dall’indirizzo, in maniera opposta a quanto accade nelle memorie ad accesso diretto e a quelle sequenziali. La RAM utilizzata nei sistemi moderni, in particolare, è una memoria a stato solido (stampata su silicio) che può essere vista, concettualmente, come una matrice di piccolissimi condensatori governati da transistor.

La carica presente in questi elementi, in particolare, in fase di lettura sarà associata dal sistema ad un valore binario (1 o 0). I condensatori, tuttavia, avranno una capacità davvero risibile, e tenderanno di conseguenza a scaricarsi abbastanza velocemente nel tempo: per questo motivo le normali RAM si dicono volatili e devono essere rinfrescate (lette e riscritte) di continuo.
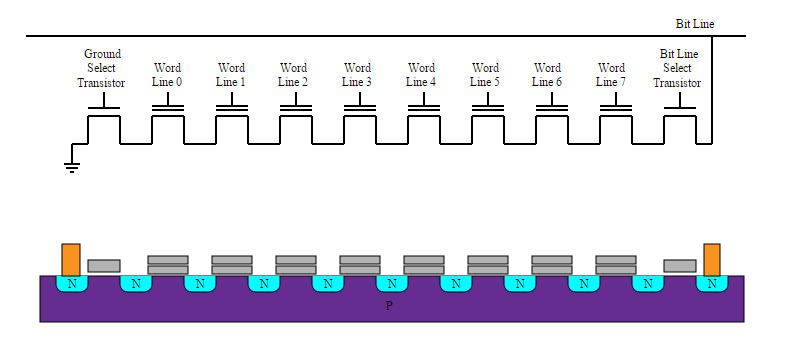
Naturalmente questo sarebbe un grande problema se le uniche memorie disponibili fossero di questo tipo, ma per fortuna esistono anche memorie a stato solido non volatili. Si tratta di quelle che siamo abituati ad indicare impropriamente con il termine ROM (read only memory) che, in realtà, è del tutto inadatto a descrivere memorie riscrivibili. I nostri smartphone, quindi, hanno di solito a disposizione una buona quantità di memoria Flash basata sull’utilizzo di un transistor floating gate MOSFET (FGMOS).

Senza addentrarci troppo nei dettagli tecnici, possiamo dire che questo tipo di transistor presenta due gate, di cui uno isolato (float). Quest’ultimo, in particolare, si comporterà come il piatto di un condensatore e, essendo completamente isolato, si scaricherà molto lentamente nel tempo. La presenza di carica nel float, d’altra parte, sarà facilmente rilevabile perché modifica la tensione di soglia del transistor.
Le memorie flash oggi più diffuse sono di tipo NAND, in cui diversi FGMOS sono collegati in serie permettendo di risparmiare spazio rispetto ad altre configurazioni. Sempre più frequenti, infine, sono i casi memorie flash che, associando più di un livello ad ogni cella, memorizzano più dati a parità di transistor sacrificando leggermente velocità e durata nel tempo (flash MLC).
Le veloci cache impiegate dentro al SoC, invece, utilizzano in maniera opposta un numero più elevato di transistor (tipicamente 6 per bit) rispetto a RAM e memorie flash e, di conseguenza, sacrificano la densità a favore della velocità di accesso ai dati.
A questo punto sarebbe naturale parlare del processo litografico che consente la stampa di tutti questi chip che, di fatto, non è molto diverso da quello che abbiamo già incontrato parlando della produzione bulk di sensori MEMS. Per questo motivo vi rimandiamo a quell’articolo per i primi dettagli su questa tecnologia, che sarà comunque approfondita la prossima volta insieme ai dettagli sui più recenti sistemi produttivi e sulla corsa alla miniaturizzazione e alle prestazioni!
")
