






Scriviamo questo articolo con un po’ di malinconia, perché segna la fine del nostro lungo viaggio verso il cuore dei moderni smartphone. Ora che abbiamo analizzato i principi di funzionamento di tutti i principali componenti, infatti, per giungere alla nostra meta ci rimangono da affrontare solo le tendenze tecnologiche che stanno già rivoluzionando il mondo dei SoC e delle memorie che consentono il funzionamento dei nostri dispositivi.
L’articolo odierno tuttavia non segnerà l’estinzione della rubrica “Tecnologia e Futuro“, ma solo la fine di un primo ciclo di articoli che, nelle nostre intenzioni, rappresentano un bagaglio utile al lettore più curioso. La magnifica imprevedibilità dello sviluppo tecnologico e la vastità del mercato, d’altra parte, non ci hanno consentito di approfondire esaustivamente ogni argomento: anche se con un ritmo più rilassato, dunque, in futuro cercheremo di mantenere il passo con l’evoluzione tecnologica analizzando i prodotti più innovativi ogni qual volta si avvicineranno alla commercializzazione.

Gli argomenti con cui chiuderemo questo ciclo, d’altra parte, sono tra quelli più amati dai consumatori e, di conseguenza, sentiti dai costruttori. Parleremo infatti della corsa alle prestazioni, di quella all’efficienza (che si riflette sull’autonomia) e delle nuove tecnologie che promettono di conciliare questi due obiettivi con costi di produzione accessibili.
È inutile negarlo: non esiste individuo che non sia affascinato da un dispositivo capace di rispondere senza incertezze e tentennamenti a qualsiasi comando. La perenne corsa alle prestazioni ingaggiata da tutti i principali chipmaker, comunque, non risponde solo a questo amore (innato ma comprensibile) verso una buona esperienza d’uso, ma anche alle crescenti necessità di software sempre più complessi ed esigenti.
Per capire come questo ambito obiettivo sia raggiungibile, possiamo fare un paragone natalizio tra il lavoro svolto dai nostri dispositivi e quello di alcuni elfi che impacchettano doni per conto di Babbo Natale. Questi ultimi hanno a disposizione due strade principali per essere certi di completare l’opera entro il 25 Dicembre: possono essere molto rapidi nel creare la singola confezione, o possono chiamare in aiuto tutti i loro amici suddividendo il lavoro da svolgere in modo da affrontarlo con più tranquillità.
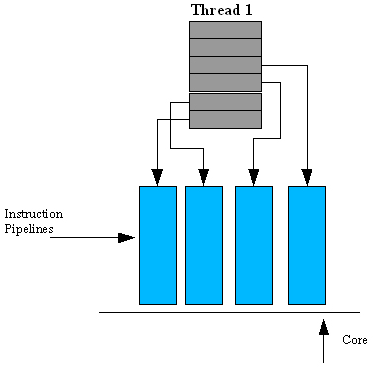
I chipmaker, allo stesso modo, possono disegnare i propri dispositivi in modo da lavorare a frequenze elevate o, in alternativa, possono puntare sul parallelismo. Il primo approccio, tuttavia, ha il grave difetto di portare ad architetture poco efficienti dal punto di vista energetico ed è ostacolato dai limiti naturali del processo produttivo utilizzato, mentre il secondo è di solito più complesso da realizzare e, di conseguenza, costoso.
A questo punto dobbiamo necessariamente distinguere le tecnologie a seconda della tipologia di circuito in cui sono impiegate. Se ci riferiamo ad una CPU, ad esempio, dovremo notare che a livello del singolo core è conveniente sfruttare l’ILP (instruction level parallelism) con l’uso di architetture superscalari dotate di pipeline abbastanza lunghe. L’utilizzo di molti stadi brevi e semplici, inoltre, consente di procedere anche sulla via delle elevate frequenze operative, che sono irraggiungibili con circuiti troppo complessi. L’utilizzo di tutte quelle tecnologie che abbiamo incontrato domenica scorsa, invece, consente di ottenere core grossi ma dall’alto IPC (instruction per clock).

Dobbiamo ricordare, comunque, che l’utilizzo di pipeline molto lunghe esaspera il problema dei salti condizionati che, se non correttamente previsti, portano alla perdita di preziosi cicli di clock in maniera proporzionale al numero degli stadi. Questo difetto ha decretato, insieme ai famosi problemi di surriscaldamento dell’architettura Netburst utilizzata sui Pentium IV (che contava su pipeline lunghe più di 30 stadi), la fine della corsa alla frequenza e una parallela crescita d’attenzione verso l’aumento dell’IPC e lo sviluppo di soluzioni multicore.
Si è notato, infatti, che spesso è preferibile l’uso di un livello più elevato di parallelismo, basato direttamente sulla concorrenzialità dei thread e dei processi. In questo caso non sarà compito del processore capire quali istruzioni possono essere elaborate in parallelo, ma sarà lo stesso programma (o la coesistenza di più programmi in conteporanea) a definire più flussi di istruzioni indipendenti tra loro.
In presenza di software ottimizzato, dunque, può essere conveniente l’utilizzo di un numero elevato di core più piccoli e lenti, che sacrificano la potenza computazionale a favore dell’efficienza energetica. Questo approccio, che già da tempo è alla base delle moderne GPU (che possono calcolare ogni pixel o gruppo di pixel in maniera parallela), ha visto una progressiva diffusione anche nel mondo dei processori per computer e smartphone.
La bontà di tale soluzione, tuttavia, è fortemente dipendente dal tipo di software utilizzato e dalla sua ottimizzazione. Se può essere relativamente facile esplicitare a livello di thread il parallelismo di un gioco separando il motore fisico dall’intelligenza artificiale, ad esempio, la creazione di un numero elevato di sottoprocessi ben bilanciati si può spesso dimostrare una sfida molto impegnativa.
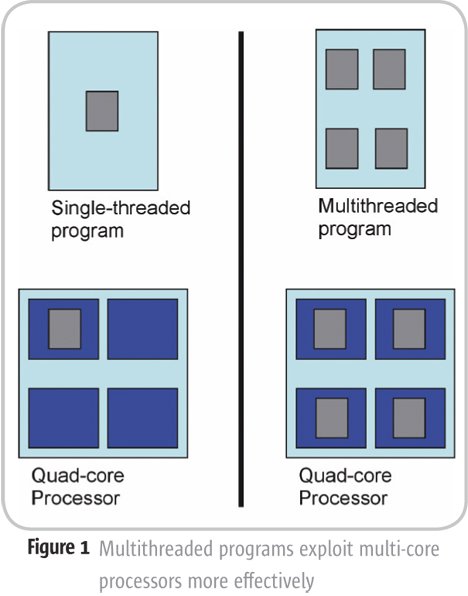
A questo punto, molto probabilmente, vi starete chiedendo se le app andorid che utilizzate più frequentemente sono adeguatamente ottimizzate o se, in maniera opposta, il SoC multicore presente nei vostri dispositivi è costretto a lavorare al di sotto delle sue possibilità. Premettendo che non è facile dare una risposta a questa domanda (che dipenderebbe naturalmente dal tipo di uso che fate del terminale), possiamo dirvi che in genere l’utilizzo di processori quad-core risulta più che giustificato.
Secondo alcuni recenti test, infatti, nella maggior parte degli scenari d’uso è possibile trarre vantaggio nella vita reale della presenza di quattro core, mentre l’utilizzo di un numero più elevato di core omogenei (come quelli dell’apprezzato Helio X10) garantisce un incremento prestazionale solo con un numero limitato di applicazioni. Dobbiamo puntualizzare, comunque, che alcuni degli scenari più importanti (come la navigazione web o l’aggiornamento delle applicazione dal market) riescono a sfruttare completamente otto core, dando un senso a molti prodotti attuali e futuri.

Non possiamo dimenticare, infine, che la velocità dell’intero sistema non dipende solo da quella della CPU, ma anche dalle memorie. Pure in questo caso si possono seguire le strade della frequenza e del parallelismo che, come al solito, si scontrano rispettivamente contro i limiti del consumo e della complessità.
Per quanto riguarda la memoria principale (RAM), comunque, dobbiamo chiarire che la maggior parte dei problemi derivano dal fatto che questo componente è collegato al SoC da un bus che, di solito, passa fisicamente dalla scheda madre. Sia il numero di link che la loro frequenza massima, infatti, sono limitati da questa caratteristica: il primo è così collegato al costo della scheda ed al numero di saldature necessarie, mentre la seconda è seriamente condizionata dal fatto che il segnale elettrico deve attraversare più contatti.
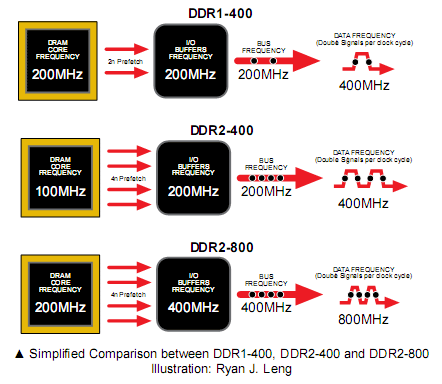
Per ottenere bandwidth elevate, dunque, attualmente si utilizza la tecnologia DDR (double data rate) per inviare dati sia sul fronte di salita che su quello di discesa del clock, ottenendo bandwidth elevate a frequenze relativamente basse. Utilizzando prefetch sempre più evoluti (che leggono nello stesso momento più bit di una singola colonna) e migliorando il collegamento fisico, poi, l’industria tecnologica è riuscita lentamente ad aumentare anche le frequenze di queste memorie. Per il futuro, infine, sembra che la strada sia segnata verso una maggiore integrazione tra RAM e SoC, magari con l’uso di chip 3D.
È interessante notare come la diffusione di SoC con core eterogenei, cioè diversi tra loro ed adatti a scenari d’uso diversi, stia diventando sempre più vasta e capillare. Oltre ai tanti sistemi big.LITTLE, in futuro vedremo poi anche soluzioni con più cluster (come il decacore Helio X20) che promettono prestazioni incredibili e ottimi consumi. Non dobbiamo credere, tuttavia, che la tecnologia impiegata in questi SoC nasca solo per segnare nuovi traguardi nella corsa alle performance, che anzi sono ritenute spesso secondarie rispetto al guadagno in efficienza.
Per capire bene la necessità di questi sistemi faremmo bene a ricordare che, per qualsiasi chip basato sull’uso di transistor CMOS (come i nostri SoC), i consumi possono dipendere da tre tipi diversi di dissipazione di energia: dinamica, di corto circuito e per il leakage. I consumi dinamici, in particolare, dipendono dal fatto che i transistor possiedono una (seppur piccolissima) capacità interna. Ogni cambio di stato, dunque, corrisponde a scaricare e ricaricare numerosissimi condensatori, con un conseguente spreco di energia.
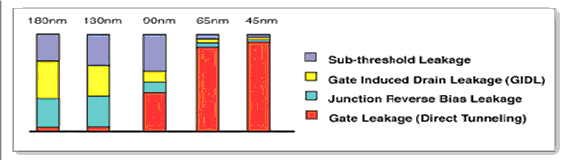
Può accadere, poi, che per un brevissimo momento più transistor si trovino nella loro fase conduttiva creando un cortocircuito tra il polo positivo e quello negativo dell’alimentazione. Esistono, infine, delle correnti di leakage che, causate per lo più da effetti quantistici, sono oggi un ostacolo fondamentale alla riduzione dei consumi dei sistemi elettronici. All’aumentare del numero di transistor coinvolti, naturalmente, cresceranno anche queste potenze dissipate.
Empiricamente, inoltre, si può notare che il consumo di un qualsiasi processore dipende linearmente dalla frequenza e circa quadraticamente dalla tensione operativa. Ogni aumento della frequenza di un circuito, poi, è di solito legato ad un analogo innalzamento della tensione operativa, necessario per evitare di incorrere in errori di calcolo. Questo vuol dire, all’atto pratico, che esiste una curva che stabilisce quale sia la frequenza energeticamente ottimale per ogni circuito.
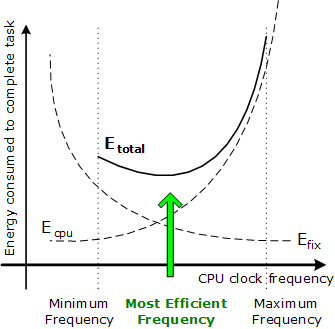
La via per l’efficienza, dunque, è assai stretta e passa da un buon compromesso tra circuiti complessi (che consumano molto a causa dell’elevato numero di transistor) e circuiti semplici (che non potendo scalare in frequenza sono inadatti a carichi gravosi). In ambiti dove la riduzione della potenza dissipata non è fondamentale spesso sono sufficienti sistemi di clock gating, che consistono nella diminuzione della frequenza operativa quando non è necessaria tutta la potenza di calcolo, e di power gating, cioè di “spegnimento” delle parti inutilizzate del circuito.
L’architettura big.LITTLE, da questo punto di vista, segna una grossa evoluzione sul fronte dell’efficienza grazie all’utilizzo dei core più adatti per ogni scenario. Potete immaginare questi SoC, dunque, come una costellazione di processori e circuiti che vengono alimentati solo quando devono essere utilizzati, con due CPU parallele (di solito quad-core) che hanno accesso alla stessa memoria e si alternano in base al carico di lavoro.
Non possiamo ignorare, comunque, che alcuni importanti produttori (Qualcomm su tutti) preferiscano puntare su tecniche avanzate di risparmio energetico e su SoC dotati dei soli quattro core “big”. Questo approccio, magari affiancato dall’uso di tecniche litografiche particolarmente avanzate, ha dimostrato nel tempo di essere ancora valido.
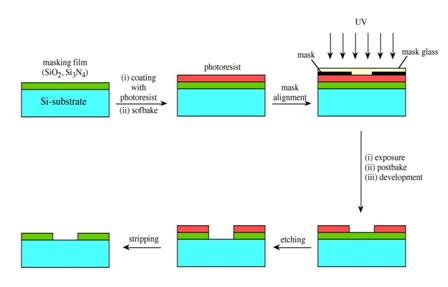
Finora abbiamo parlato delle prestazioni e dei consumi a livello di circuiti logici, ma il nostro discorso sarebbe assolutamente incompleto se trascurassimo le tante tecnologie produttive che, in futuro, permetteranno di portare efficientemente i progetti dei chipmaker su silicio. Non ci riferiamo, quindi, al processo fotolitografico di base (che abbiamo già incontrato nelle scorse settimane) basato sull’uso di photoresist, ma alle tante tecnologie aggiuntive che stanno alla base del proseguimento della corsa alla miniaturizzazione.
Prima di procedere oltre, tuttavia, dobbiamo fermarci un momento per un giusto tributo alla legge di Moore che accompagna e guida lo sviluppo dei circuiti integrati sin dal 1965. In un articolo di quell’anno, infatti, il futuro cofondatore di Intel notò che la complessità dei microprocessori (e di conseguenza il numero di transistor utilizzati) raddoppiava ogni circa dodici mesi. Da allora questa legge empirica, a meno di piccole modifiche (ora i mesi sono 18) ha costituito un riferimento fondamentale per tutte le aziende attive nel campo della produzione di processori.
A questo punto dobbiamo notare che i costi produttivi di un SoC sono decisamente legati alle sue dimensioni, in quanto chip più grandi hanno maggiore probabilità di presentare imperfezioni e, di conseguenza, di essere scartati in fase di selezione (si dice che hanno bassi yeld). Appare ovvio, dunque, che l’unica via rimasta per estendere la legge di Moore a costi ragionevoli (e di incrementare la potenza dei processori) è quella di creare chip con transistor sempre più piccoli.
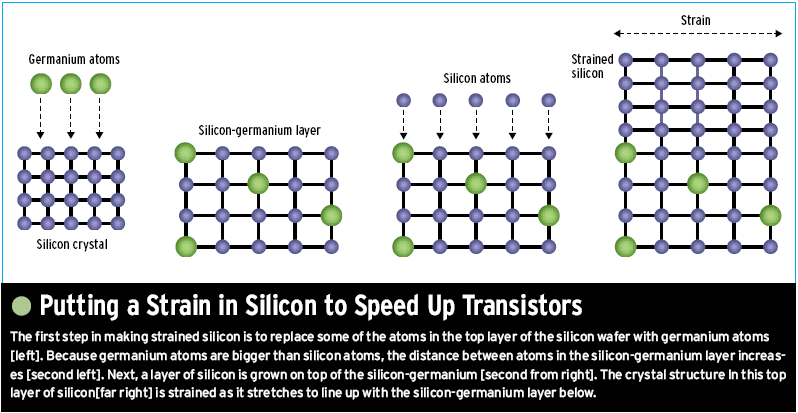
Nel tempo siamo quindi arrivati quasi ai limiti fisici del silicio, con transistor che hanno gate nell’ordine della decina di nanometri. Per migliorare le caratteristiche elettroniche, dunque, si sono utilizzate tecniche come lo strained silicon, che consiste nello “stirare” i piani del cristallo di silicio per facilitare la mobilità elettronica.
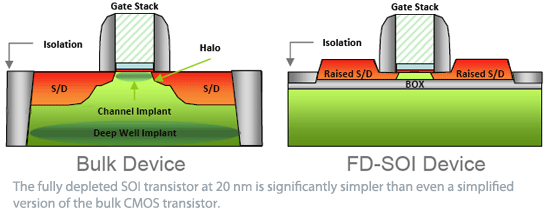
Per diminuire gli effetti del leakage, inoltre, molte aziende si sono affidate al SOI (silicon on insulator), cioè alla tecnologia che consente di sostituire il semplice substrato in silicio con uno che contiene un sottile layer di diossido di silicio isolante.
L’utilizzo di materiali con elevata costante dielettrica (HKMG), poi, si è reso indispensabile per evitare che l’uso di strati isolanti sempre più sottili rendesse probabile l’insorgenza dell’effetto tunnel. Grazie alle caratteristiche di questi materiali, dunque, è stato possibile incrementare la forza del campo elettrico dentro i transistor pur mantenendo strati più spessi.
Per quanto riguarda le connessioni, invece, si tenderà ad utilizzare materiali con costante dielettrica sempre più bassa, cioè conduttori sempre migliori, per diminuire i ritardi dovuti all’inevitabile presenza di capacità e resistenze parassite. Impilando diversi chip con contatti verticali chiamati TSV (through-silicon via), d’altra parte, sarà possibile aumentare la superficie reale dei circuiti senza abbassare le rese produttive, e avvicinare il SoC agli altri chip principali (RAM su tutti) creando chip 3D. Una versione semplificata di questa tecnologia è HBM che, in altri campi, già oggi permette l’utilizzo di memorie 3D.
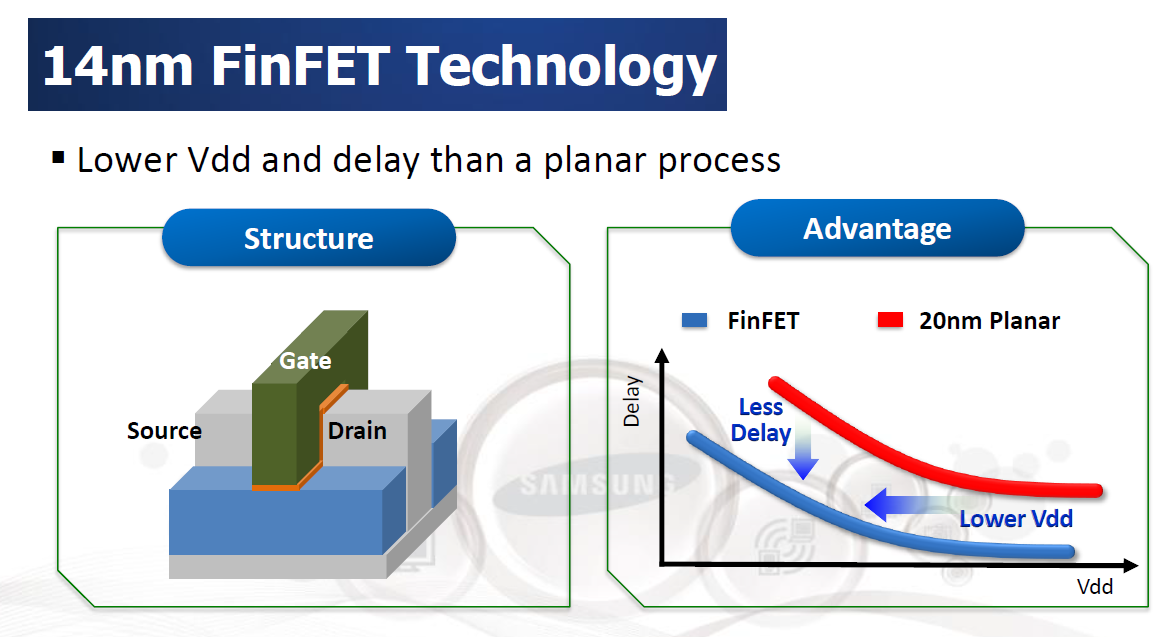
Grande risalto è poi dato allo sviluppo di transistor multigate, come i celebri FinFet o quelli trigate di Intel. Si tratta, di fatto, di moltiplicare il numero di gate per aumentare l’area su cui possono scorrere gli elettroni e, contemporaneamente, rimuovere tutto il silicio che non è parte del canale creando delle sottili “pinne”. In questo modo si eliminano alcuni effetti indesiderati dovuti alle capacità parassite, consentendo di diminuire la tensione di funzionamento del circuito a parità di frequenza.
La necessità di stampare strutture sempre più piccole, per concludere, porterà inevitabilmente al’uso di litografie basate su EUV (extreme ultraviolet lithography) o su EBL (Electron Beam Lithography), cioè su raggi molto energetici. Queste due tecnologie, tuttavia, attualmente presentano numerosi difetti, e non sono affatto pronte per il mercato. Per questo sono state proposte anche tecniche di Nanoimprint Lithography, basate sulla trasmissione meccanica del pattern da stampare, che però hanno ancora seri problemi di affidabilità.
Ci piacerebbe, infine, concludere questo articolo parlando di tutte quelle tecnologie che prevedibilmente eviteranno l’uso dei classici transistor in silicio, come il grafene o i computer quantistici. Dato che si tratta di sistemi ancora prototipali ed eccezionalmente lontani dalla commercializzazione in ambito mobile, tuttavia, questa volta non cederemo alla tentazione di parlarne. Vi salutiamo, dunque, con la sola speranza di una loro futura diffusione!
")
