
")
")

")

Un nuovo studio pubblicato dai ricercatori di Cupertino svela UniGen 1.5, un tentativo ambizioso di consolidare all’interno di un unico modello unificato tre pilastri fondamentali dell’AI: la comprensione, la generazione e l’editing delle immagini.
Apple UniGen 1.5: l’evoluzione verso un sistema onnicomprensivo
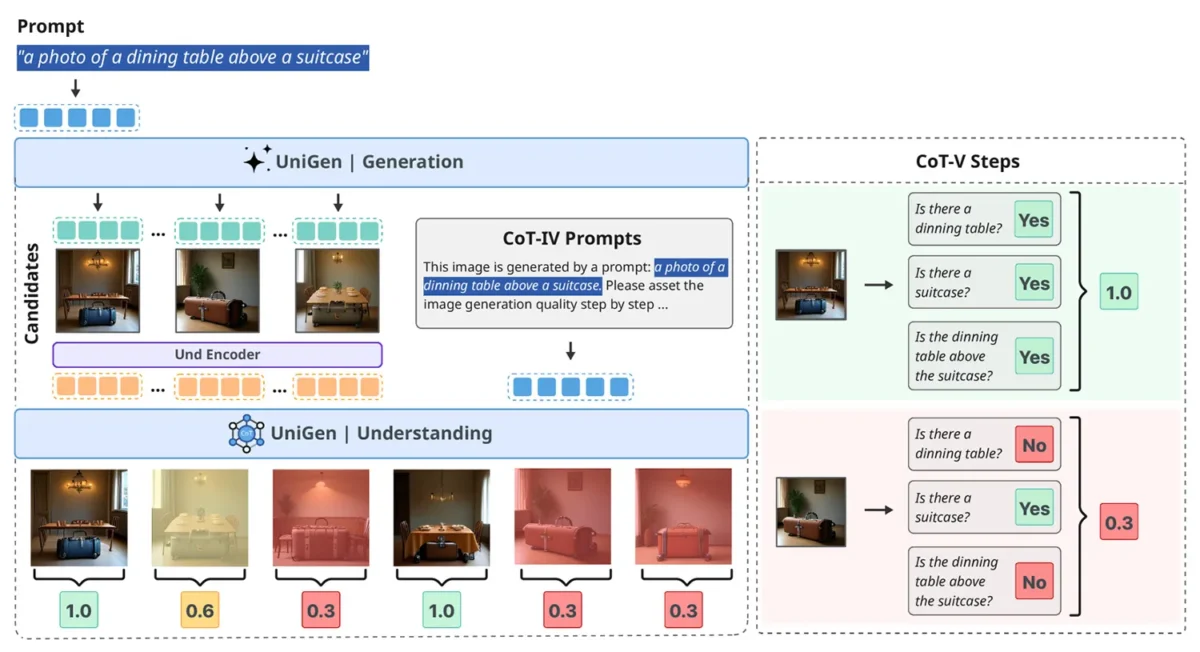
Le basi di questo progetto erano state gettate lo scorso maggio con la pubblicazione del primo studio su UniGen, che proponeva un Large Language Model multimodale capace di gestire sia la comprensione che la generazione di immagini senza affidarsi a sistemi separati. Con UniGen 1.5, Apple alza l’asticella estendendo le capacità del framework originale per includere anche l’editing delle immagini.
L’unificazione di queste capacità in un singolo sistema rappresenta una sfida tecnica notevole. Tradizionalmente, la comprensione e la generazione richiedono architetture e approcci differenti.
I ricercatori di Apple, tuttavia, sostengono che un modello unificato possa sfruttare le proprie capacità di comprensione semantica per migliorare drasticamente la qualità della generazione e della modifica, creando un circolo virtuoso tra le diverse funzionalità.
L’innovazione sta nell’allineamento delle istruzioni
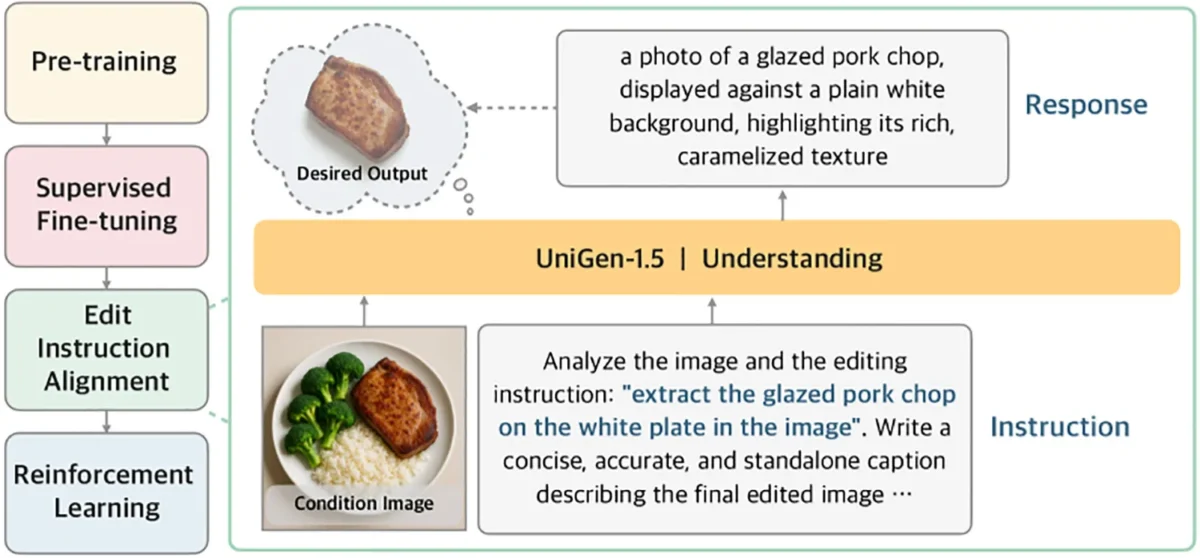
Uno dei problemi principali riscontrati nei modelli attuali riguarda la difficoltà nel recepire istruzioni di editing complesse, specialmente quando le modifiche richieste sono sottili o altamente specifiche. Per ovviare a questo ostacolo, UniGen 1.5 introduce una nuova fase di post-addestramento denominata “Edit Instruction Alignment” (Allineamento delle Istruzioni di Modifica).
Invece di chiedere direttamente al modello di modificare un’immagine, i ricercatori hanno inserito un passaggio intermedio cruciale. Il sistema viene addestrato a prevedere una descrizione testuale dettagliata dell’immagine di destinazione, basandosi sull’immagine originale e sull’istruzione fornita.
In termini pratici, il modello viene forzato a “visualizzare a parole” il risultato finale prima di generarlo graficamente. Questo passaggio permette al sistema di interiorizzare meglio l’intento della modifica, migliorando l’allineamento tra la richiesta dell’utente e la semantica dell’immagine prodotta.
Solo successivamente viene applicato l’apprendimento per rinforzo, che utilizza un sistema di ricompensa unificato sia per la generazione che per l’editing, un contributo metodologico che gli autori dello studio definiscono fondamentale.
Prestazioni competitive e benchmark di settore
I risultati di questo approccio integrato sembrano dare ragione al team di Apple. Quando testato su benchmark standard del settore, progettati per misurare la fedeltà alle istruzioni e la qualità visiva, UniGen 1.5 ha mostrato prestazioni che eguagliano o superano diversi modelli multimodali all’avanguardia.
Nello specifico, il modello ha ottenuto punteggi di 0.89 su GenEval e 86.83 su DPG-Bench, distanziando significativamente metodi recenti come BAGEL e BLIP3o. Per quanto riguarda l’editing delle immagini, UniGen 1.5 ha raggiunto un punteggio complessivo di 4.31 su ImgEdit.
Questo risultato lo pone al di sopra di modelli open-source recenti come OminiGen2 e lo rende competitivo persino nei confronti di modelli proprietari avanzati come GPT-Image-1. Questi dati confermano che l’approccio unificato fornisce una base solida per il futuro dei modelli multimodali.



Le sfide ancora aperte
Nonostante i notevoli progressi, il documento mantiene un tono di onestà intellettuale riguardo ai limiti attuali della tecnologia. I ricercatori hanno notato che UniGen 1.5 fatica ancora nella generazione di testo leggibile all’interno delle immagini. Il “detokenizer” discreto e leggero utilizzato dal sistema non riesce sempre a controllare i dettagli strutturali fini necessari per rendere accuratamente i caratteri testuali.
Un’altra area critica riguarda la coerenza dell’identità del soggetto. In alcuni casi, durante le operazioni di editing, si verificano cambiamenti indesiderati nei dettagli intrinseci, come la texture della pelliccia di un gatto o il colore delle piume di un uccello.
Queste “allucinazioni” visive indicano che, sebbene Apple abbia fatto un passo avanti decisivo, la strada verso la perfezione nella generazione multimodale richiede ancora ulteriore ricerca e affinamento.

