





Questa settimana abbiamo deciso di non rispettare le vecchie abitudini, che vorrebbero due articoli di questa rubrica dedicati rispettivamente ad aspetti attuali e prospettive future di uno stesso componente, e abbiamo diviso lo spazio a nostra disposizione fra due tecnologie molto diverse tra loro.
Se domenica ci siamo spesso allontanati dal cuore dei nostri smartphone per descrivere le costellazioni GPS e GLONASS che rendono possibile il posizionamento satellitare, dunque, oggi resteremo sulla superficie del pianeta per analizzare un sistema che, a quella distanza dalla nostra atmosfera, avrebbe ben poco senso: il comparto audio dei nostri smartphone.

In questo articolo, in particolare, seguiremo il viaggio di un segnale sonoro attraverso il microfono dei nostri dispositivi fino alla loro memoria, per poi tracciarne il tragitto inverso fino alle nostre orecchie. Sarà un percorso lungo ma affascinante che, se seguito nella sua interezza, chiarirà molti dettagli di una tecnologia già matura ma comunque fondamentale.
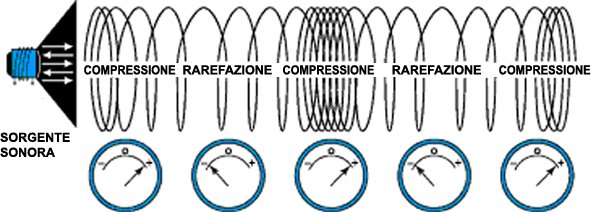
Il suono, sia che sia prodotto dall’abilità di un musicista virtuoso che dalla temibile attività di un trapano da dentista, non è altro che un insieme di onde vibrazionali che si propagano nella direzione in cui un mezzo (a noi interessa l’aria, ma potrebbe essere anche un solido o un liquido) viene compresso. Le onde di questo tipo, in particolare, si dicono longitudinali.
Indipendentemente da quale sia l’origine delle vibrazioni, dunque, il microfono dei nostri dispositivi (che abbiamo già descritto in un precedente articolo) percepirà una variazione di pressione lungo la direzione di propagazione dell’onda, che sarà convertita in un segnale elettrico. L’informazione raccolta in questo modo dal microfono è tuttavia analogica e, di conseguenza, incomprensibile dai SoC dei nostri smartphone che ragionano in modo digitale.
Affinché il segnale sia utilizzabile, quindi, è necessario che venga processato da un ADC (Analog to Digital Converter) che lo traduca in stringhe di codice binario. Prima di descrivere i principi alla base di questo componente, tuttavia, è indispensabile introdurre un paio di concetti teorici che sono alla base del funzionamento dell’intero sistema.
Dobbiamo citare, ad esempio, il teorema di Fourier che ci assicura sia possibile scomporre qualsiasi funzione periodica, per quanto complicata, in una somma (eventualmente infinita) di onde sinusoidali. Questo vuol dire in pratica che al posto di considerare un suono generico (che potrebbe essere sia la musica più soave che il rumore più fastidioso, indipendentemente dal timbro) potremo limitarci, per linearità, al semplice caso sinusoidale senza che il discorso perda di generalità.
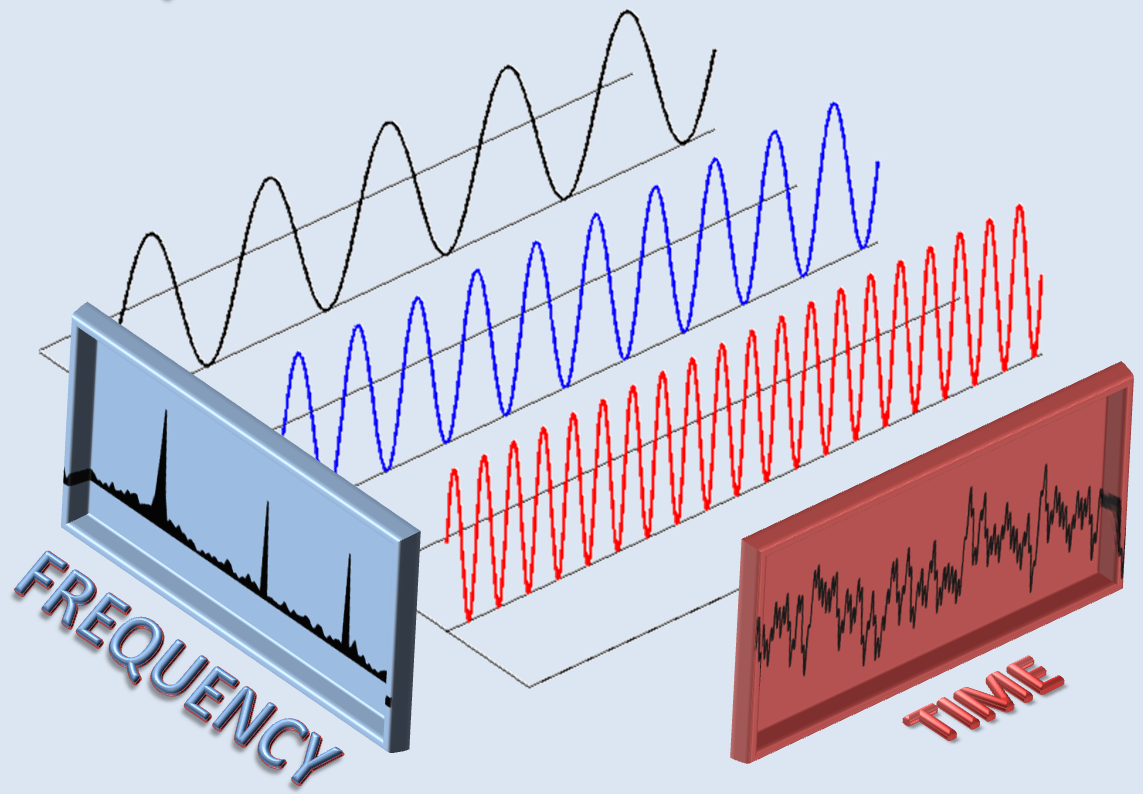
Per un onda di questo tipo, in particolare, appaiono chiari i concetti di frequenza (il numero di volte in cui l’onda si ripete in un secondo, si misura in Herz) e di ampiezza, cioè lo spostamento massimo delle molecole d’aria dalla posizione di equilibrio (o la tensione da un picco all’altro dell’onda in caso di segnale elettrico). È interessante notare, inoltre, come un orecchio umano in buone condizioni sia sensibile solo ad onde di frequenza compresa all’incirca tra 20 Hz e 20000 Hz, e che quindi tutte le onde fuori da questa banda si possano trascurare senza una sensibile perdita di qualità.
Questa caratteristica delle nostre orecchie è fondamentale per la digitalizzazione del suono in quanto permette l’intervento del teorema del campionamento di Nyquist-Shannon. Questo rilevante risultato teorico, infatti, ci assicura che sia possibile campionare un segnale analogico a banda limitata senza perdita di informazioni purché la frequenza di campionamento sia maggiore di quella di Nyquist (pari al doppio della frequenza massima del segnale).
Detto in parole più semplici questo teorema ci assicura che, scattando più di 40000 “foto” del segnale, sia possibile ricostruirlo esattamente nella banda di frequenze in cui l’orecchio umano è sensibile. Il primo passo che deve compiere un ADC, di conseguenza, è rimuovere le componenti dell’onda sonora (diventata segnale elettrico grazie al microfono) di frequenza troppo elevata che, pur non essendo percepibili dall’uomo, creerebbero errori se campionate.
Se nel segnale fossero presenti anche frequenze maggiori alla metà di quella di campionamento, infatti, si avrebbe la comparsa di aliasing: in fase di ricostruzione il DAC non saprebbe distinguere i dati generati dal campionamento di queste onde con quelli dovuti a frequenze più basse e, di conseguenza, riprodurrebbe un suono ben diverso da quello originale. Una frequenza di campionamento elevata, dunque, è meno sensibile alla bontà dei filtri in ingresso e permette teoricamente di registrare suoni oltre la banda udibile.
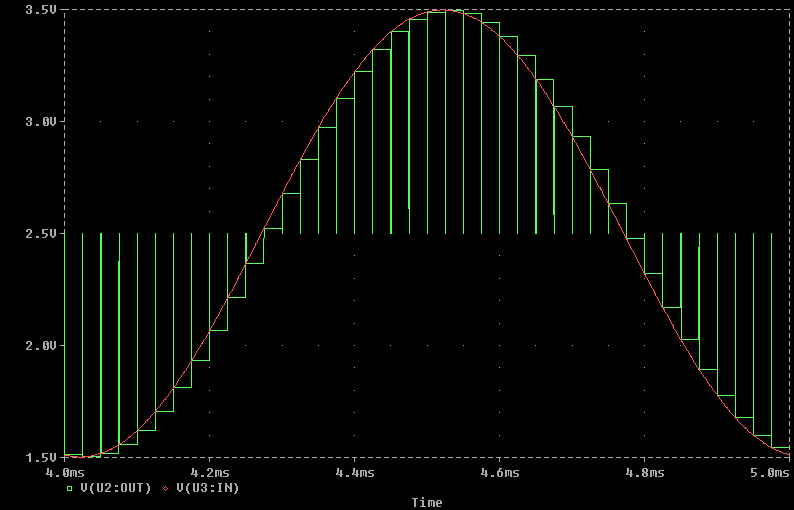
A valle dei potenti filtri passa basso che limitano la banda del segnale, quindi, quest’ultimo deve essere campionato, cioè “fotografato” tramite un circuito di sample and hold (che nella versione più semplice è composto da un condensatore, un interruttore ed un transistor) che lo blocchi il tempo necessario a quantizzarlo. Il processo di quantizzazione consiste nel confrontare il campione di segnale con una scala (numerata in binario) di livelli, e come risposta restituisce il numero del gradino che approssima meglio il segnale.
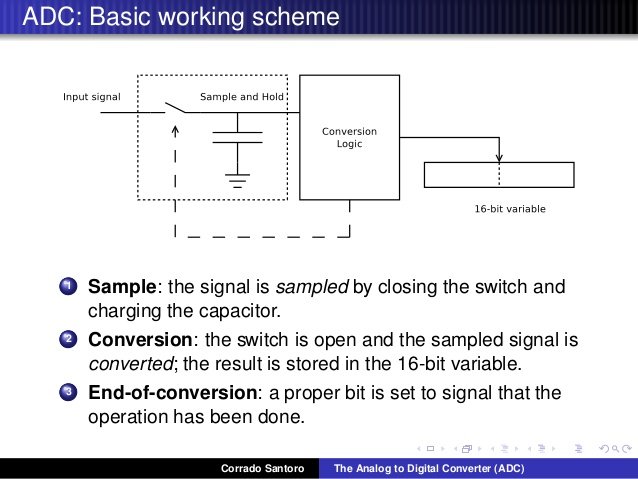
In questo modo, dunque, l’onda sonora è codificata in formato PCM (Pulse-code modulation, in realtà è solo una delle possibili modulazioni) che, essendo digitale, è finalmente del tutto comprensibile dal resto dei circuiti del SoC.
Notiamo, infine, che frequenza di campionamento oggi più utilizzata è ancora quella a 44.1 kHz, che si è affermata in seguito alla diffusione dei CD, e che il numero di livelli della scala (che non necessariamente è lineare) si misura in bit. Un sistema con n bit, in particolare, avrà 2^n livelli, e quindi un ADC a 24 bit avrà a disposizione 16777216 gradini con un errore di quantizzazione ridotto a soli 0.06 parti per milione pari ad una gamma dinamica di 144 db .
A questo punto potremmo addentrarci con maggiore precisione nel mondo degli ADC, magari illustrando uno dei modelli più utilizzati in ambito audio (come quello ad approssimazioni successive). Un’analisi del genere, tuttavia, ricederebbe molto spazio e, probabilmente, non risulterebbe interessante per molti lettori. Abbiamo deciso, di conseguenza, di impiegare meglio questo articolo dedicando un po’ di spazio al processo di compressione che, molte volte, è causa di risultati scadenti o non in linea con le attese.
L’idea di conservare l’audio direttamente in formato PCM, d’altra parte, non è sicuramente la migliore dal punto di vista del consumo di memoria. Se una classica traccia stereo di un CD richiede circa 10 MB per ogni minuto, infatti, esistono compressioni senza perdita di informazioni (in inglese lossless) che riducono fino al 60% la necessità di memoria.
Questi sistemi sono di tipo non percettivo e si basano sull’utilizzo di algoritmi per rimuovere la ridondanza dei dati, cioè eliminare gli inutili duplicati delle informazioni. Possiamo supporre, ad esempio, che nel nostro file audio sia presente un suono che si ripropone ciclicamente sempre uguale: al posto di riscriverlo ogni volta, il codec lo scriverà una volta sola ed indicherà come si ripete.
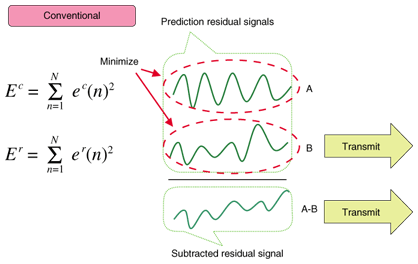
Nella realtà l’eliminazione delle ridondanze avviene in un modo un po’ più complesso, che si basa sull’uso di predizioni lineari e residui. Il codec, infatti, analizza un primo blocco temporale e, applicando un algoritmo, ricava dei parametri che permettono di approssimare il blocco temporale successivo partendo dal primo. La differenza tra la predizione software ed il segnale reale, poi, viene codificata a parte, in modo che un eventuale decoder possa ricomporre il secondo blocco senza perdita di informazioni. Ripetendo più volte il processo, infine, si codificherà l’intero file audio.
Il mondo dei sistemi non percettivi, comunque, comprende anche algoritmi di tipo lossy, cioè che comprimono l’informazione perdendone una parte. Questo si può ottenere, ad esempio, utilizzando una scala di quantizzazione non lineare che sia più sensibile ai suoni poco intensi che a quelli più intensi. In questo modo è possibile ridurre il numero di gradini, cioè il numero di bit utilizzati per ogni campione, senza perdite eccessive in qualità del segnale (questo sistema è molto utilizzato per le telecomunicazioni, che utilizzano una scala logaritmica).
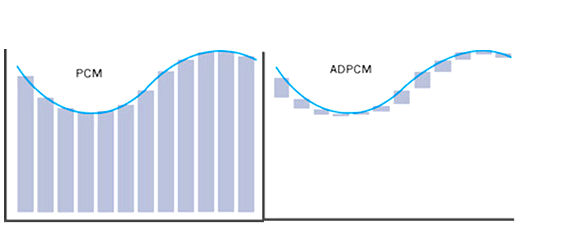
Un altra tecnica molto utilizzata, poi, è la PCM adattativa differenziale, che consiste nel codificare la differenza di ampiezza tra un campione ed il successivo. Questa quantità, infatti, nella maggior parte dei casi si mantiene abbastanza piccola e per essere misurata richiede, di conseguenza, un numero minore di bit. Nel caso in cui ci siano variazioni brusche nel suono, invece, il codec adatta il passo di quantizzazione per evitare grandi perdite di qualità.
Dato che la compressione o la qualità ottenute con questi metodi spesso non sono sufficienti, infine, è giunto il momento di tuffarci nel grande mare dei sistemi percettivi. Queste tecniche, come intuibile dal nome, si basano sul fatto che le nostre orecchie, in determinate condizioni, sembrano non essere sensibili ad alcune componenti del suono che possono quindi essere eliminate.
La scienza che studia questo fenomeno è in particolare la psicoacustica che, semplificando molto, ci dice che il contributo di una componente del suono dipende dalla sua intensità, dalla sua frequenza e dalla presenza di componenti vicine in grado di mascherarlo.
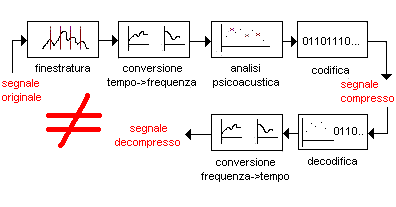
Un codec lossy di tipo percettivo, dunque, deve analizzare in frequenza il segnale di partenza, cioè lo deve trasformare in quella somma di sinusoidi che abbiamo citato parlando del teorema di Fourier. A questo punto l’algoritmo stimerà l’importanza delle singole componenti e, in base ai risultati, eliminerà quelle meno importanti. Le frequenze residue, infine, saranno compresse e, per essere riutilizzate, dovranno essere riconvertite utilizzando la trasformazione inversa.
A questo punto avrete capito che non solo l’audio finale sarà ben diverso da quello originale, ma sopratutto dipenderà dal codec utilizzato. Indipendentemente dal bitrate, in particolare, un algoritmo di scarsa qualità darà risultati scadenti, mentre uno di buona qualità riuscirà ad ottenere ottime compressioni senza (o quasi) che le nostre orecchie possano accorgersi della differenza rispetto l’originale.
Adesso che abbiamo visto come è possibile registrare ore di audio in pochissimo spazio, possiamo finalmente vedere cosa accade quando premiamo il tasto play della nostra app musicale preferita. Tralasceremo naturalmente il processo di decompressione, in cui gli algoritmi ripercorrono all’indietro la strada fatta dai codec per riprodurre un suono fedele all’originale (per quanto spesso diverso), e ci concentreremo sul DAC (Digital to Ananlog Converter) e sui “trucchi” utilizzati da questo per migliorare la riproduzione.
Prima di procedere oltre, comunque, è giusto chiarire che i processi di compressione e decompressione avvengono spesso dentro il DSP (Digital Signal Processor) integrato nel SoC. Questo componente, inoltre, si occupa spesso di applicare filtri software speciali che dovrebbero, nell’intenzione del costruttore, migliorare la gradevolezza del suono (ad esempio aumentando i bassi o creando effetti 3D).
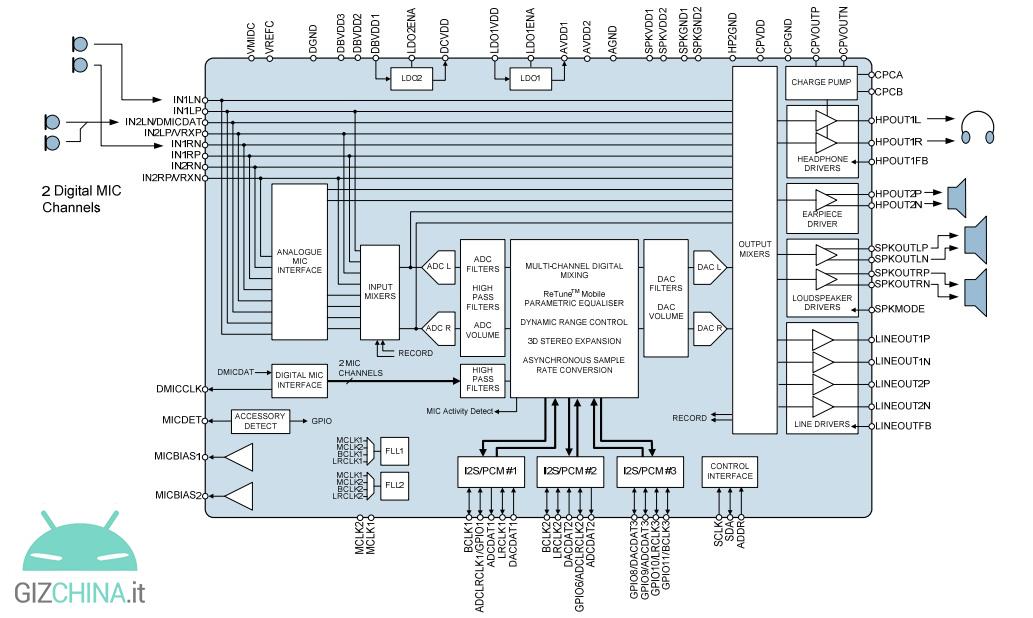
A valle di questo componente, comunque, si trova il nostro DAC che si occupa di ricreare quel segnale analogico che, attraverso uno speaker, diventa suono. Spesso i nostri smartphone possiedono un singolo chip che integra DAC e ADC (anche se questo ultimo componente è sempre più spesso già presente nel microfono), e di solito anche questi “audio hub” presentano un microcontrollore utilizzato per effetti sonori di vario tipo.
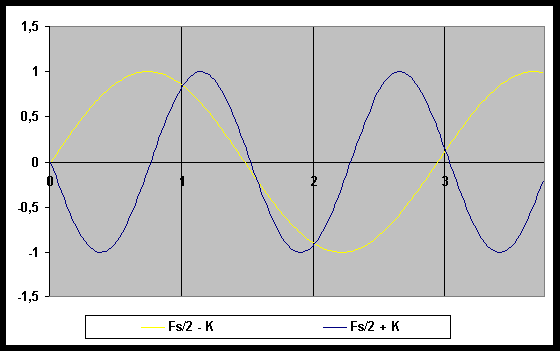
Il DAC comunque, deve risolvere alcuni dei problemi ereditati dal sistema utilizzato dall’ADC per registrare il segnale. L’aliasing, ad esempio, si manifesterà anche nella riconversione in analogico e, in presenza di una frequenza di campionamento poco superiore a quella di Nyquist, sarà difficile da eliminare a meno di utilizzare potenti (e costosi) filtri passa basso. Dato che l’aliasing sarà quasi sempre presente, dunque, si utilizza il sistema del sovracampionamento per evitare che i suoi effetti si ripercuotano nel segnale finale.
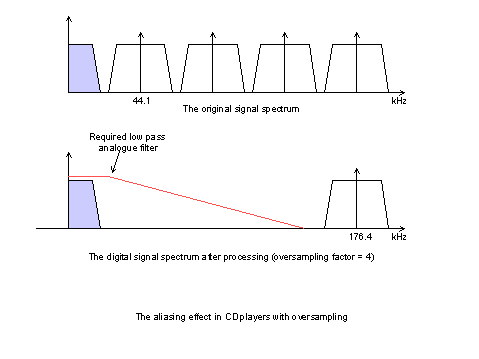
L’oversampling consiste nell’aumentare artificialmente la frequenza di campionamento introducendo dei campioni nulli, che saranno poi rimossi a valle del DAC. In questo modo l’alias è sempre presente, ma si sposta verso frequenze più elevate che sono facilmente eliminabili da filtri poco costosi e, in ogni caso, non sono udibili dall’orecchio umano e sono riprodotte molto attenuate dai comuni altoparlanti.
Per evitare i problemi dovuti alla quantizzazione del segnale (che diventa molto importante in presenza di onde poco ampie) sarà poi necessario un processo di dithering. Immaginiamo, ad esempio, un’onda sinusoidale di piccola ampiezza che viene registrata solo dal bit più sensibile.
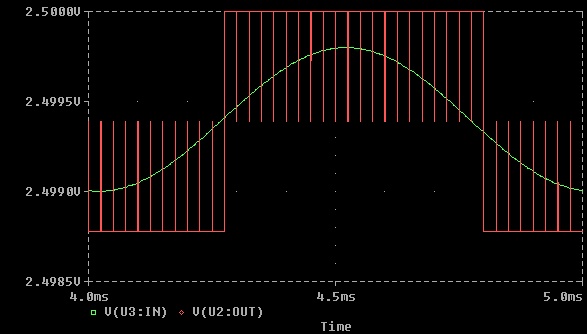
In questo caso l’onda originale sarà agli occhi del DAC un’onda quadra periodica che, se riprodotta, sarebbe sentita dall’orecchio umano come una distorsione. Se si introduce un rumore di fondo ad alta frequenza, detto dither, si può tuttavia mascherare la presenza di quest’onda poco gradita alle nostre orecchie. Il dithering, dunque, “baratta” una distorsione con un rumore.
Il DAC, comunque, si occupa di ricreare la forma d’onda originaria utilizzando al contrario la scala utilizzata dall’ADC. Una volta ricevuto il numero del gradino (ne riceve più di 40000 al secondo), dunque, questo circuito emette al livello corrispondente. Il segnale finale, dunque, sarà uguale (entro gli errori di quantizzazione e di campionamento) a quello iniziale e potrà essere indirizzato ad un amplificatore.
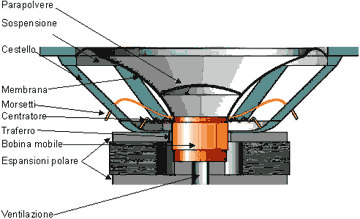
A valle dell’amplificatore, che si occupa di aumentare l’ampiezza del segnale (guadagno) e la sua potenza, c’è infine lo speaker che, grazie alla sua bobina mobile, trasforma il segnale elettrico in una vibrazione che si diffonde nell’aria e, finalmente, giunge alle nostre orecchie.
Speriamo che questo piccolo viaggio nel mondo del suono vi sia piaciuto e che, anche se non abbiamo toccato moltissimi degli argomenti più cari al pubblico audiofilo, vi siate fatti un’idea del funzionamento del comparto audio dei nostri smartphone. Vi comunichiamo, per concludere, che la prossima volta nella nostra rubrica “Tecnologia e Futuro” parleremo dei sistemi di telecomunicazione che sono alla base della parte “phone” (e non solo) dei nostri dispositivi!

